Table of Contents
This appendix summarizes syntax information about the commonly used SGML markup declarations and other constructs for quick reference. The following constructs are described:
Element declarations (Section A.1, “Element Declarations”)
Attribute definition list declarations (Section A.2, “Attribute Definition List Declarations”)
General and parameter entity declarations (Section A.3, “Entities ”)
Comments and comment declarations (Section A.4, “Comments ”)
Marked section declarations (Section A.5, “Marked Section Declarations”)
Notation declarations (Section A.6, “Notation Declarations”)
Processing instructions (Section A.7, “Processing Instructions”)
Document type declarations (Section A.8, “Document Type Declarations”)
SGML declarations (Section A.9, “SGML Declarations”)
Formal public identifiers and catalogs (Section A.10, “Formal Public Identifiers and Catalogs”)
The syntax diagrams in this appendix use the following conventions:
Curly braces ( { } ) surround choices among which one must be picked.
Square brackets ( [ ] ) surround choices among which one can optionally be picked. Note that in a few cases, square brackets are actually part of the SGML markup. In these cases, the brackets are shown in boldface and an explanation is provided.
An ellipsis ( ... ) follows choices that are repeatable.
Italic text represents portions of the markup declaration that the DTD implementor is responsible for supplying.
Roman text and all special characters other than those mentioned above represent SGML keywords and delimiters that must be supplied as shown.
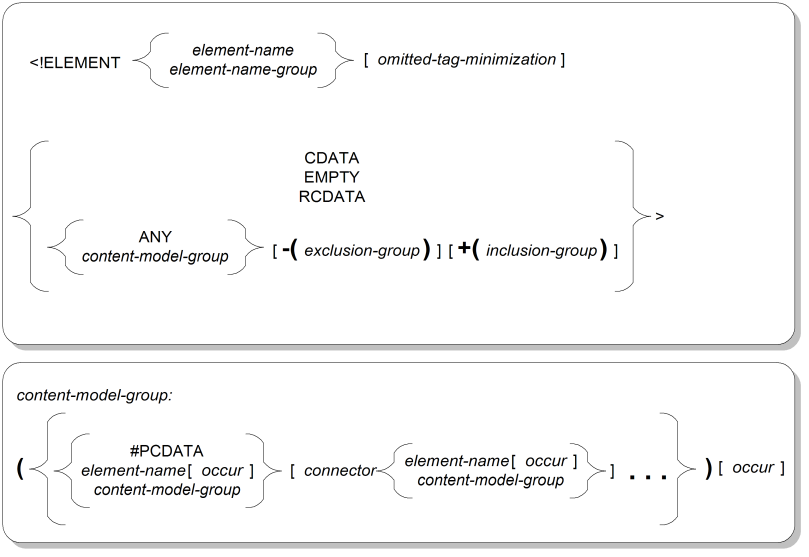
Figure A.1, “Element Declaration Syntax” shows the syntax for element declarations and content model groups.
ELEMENTKeyword that starts an element declaration.
element-name, element-name-groupThe names of the one or more elements being declared. If more than one name is supplied, the group must be surrounded by parentheses. Its components can be separated using any connector.
<!ELEMENT elem - - ...>
<!ELEMENT (elem1|elem2) - - ...>
omitted-tag-minimizationTwo fields separated by a space, indicating whether it is an error (-) or not (uppercase or lowercase O) for the start-tag and end-tag, respectively, to be omitted. These fields are optional if the feature OMITTAG feature is set to NO in the SGML declaration.
<!ELEMENT elem - - ...>
<!ELEMENT elem ...>
EMPTYKeyword indicating that the element cannot have content (and therefore, cannot have an end-tag). This keyword forms an element's declared content.
<!ELEMENT elem - O EMPTY>
CDATAKeyword indicating that the element's content consists solely of “character data,” with no entity references or subelements allowed. This keyword forms an element's declared content.
<!ELEMENT elem - - CDATA>
RCDATAKeyword indicating that the element's content consists solely of “replaceable character data,” which includes entity references but not subelements (even if they are allowed with a higher-level inclusion). This keyword forms an element's declared content.
<!ELEMENT elem - - RCDATA>
ANYKeyword indicating that the element's content can consist of a free mixture of parsed character data (explained below) and any of the elements available in the DTD.
<!ELEMENT elem - - ANY>
content-model-groupSpecification of an allowable arrangement of elements and/or data characters in an element's content. Content model groups can be nested inside other content model groups. Each level of group is surrounded by parentheses.
If a group contains more than one element or nested group, each component must be separated by a connector. Only one connector can be used inside any one level of group. The choices of connector are as follows:
,Sequential (SEQ) connector requiring each component to appear (taking into account inner occurrence indicators) in the left-to-right order supplied.
|Either-or (OR) connector requiring only one of the components to be chosen (taking into account inner occurrence indicators) exclusive of the others.
&Any-order (AND) connector requiring each component to appear (taking into account inner occurrence indicators) in any order, not just the order supplied.
<!ELEMENT elem1 - - (elem2, elem3)>
<!ELEMENT elem1 - - (elem2|(elem3, elem4))>
Any group or element name in a content model can be followed with an occurrence indicator. The choices of occurrence indicator are as follows:
By default, the element or group is required to occur exactly once in the content.
?Marker indicating that the element or group is optional (OPT ), that is, that it can occur zero times or one time.
*Marker indicating that the element or group can occur any number of times (REP), including zero.
+Marker indicating that the element or group must occur at least once and after that can occur any number of times (PLUS).
<!ELEMENT elem1 - - (elem2?, elem3)>
<!ELEMENT elem1 - - (elem2 & (elem3+, elem4*))>
#PCDATAKeyword indicating that this location in the element's content model can contain “parsed character data,” which includes characters, entity references, and any elements allowed by the current content model or by higher-level inclusions.
<!ELEMENT elem - - (#PCDATA)>
<!ELEMENT elem1 - - (#PCDATA|elem2)*>
When the keyword stands alone, whether or not an occurrence indicator is used, it still allows a free mixture of zero or more data characters.
#PCDATA should appear only by itself or in a content model containing only an optional-repeatable group, but does not generate an error if it appears in a nonrecommended configuration.
exclusion-group, inclusion-groupExceptions to the element's content model. The exclusion group indicates one or more element names to be disallowed from the content of this element and any subelements, and the inclusion group indicates one or more element names to be freely allowed in the content of this element and any subelements.
Even if only one element is supplied, the group must be surrounded by parentheses. Its components can be separated using any connector . An exclusion group must be preceded by a hyphen ( - ) and an inclusion group must be preceded by a plus sign ( + ).
<!ELEMENT elem1 - - (elem2) -(elem3)>
Exclusions take precedence over inclusions in their effect on any one content model, and any specified exclusions must appear before any specified inclusions. Elements cannot appear both as required (in the content model) and as exclusions.
Following are the SGML declaration quantities related to elements.
The number of characters in an element name cannot exceed NAMELEN, which is 8 in the reference quantity set.
The number of nesting levels of content model groups in any one content model, including the top level, cannot exceed GRPLVL, which is 16 in the reference quantity set.
The number of content tokens (element names, the #PCDATA keyword, and content model groups) in any one content model group cannot exceed GRPCNT, which is 32 in the reference quantity set.
The number of content tokens in any one entire content model cannot exceed GRPGTCNT, which is 96 in the reference quantity set.
The nesting depth of open elements cannot exceed TAGLVL, which is 24 in the reference quantity set.
The number of characters in a start-tag, including the element name and all attribute names and values but not including the tag delimiters, cannot exceed TAGLEN, which is 960 in the reference quantity set.
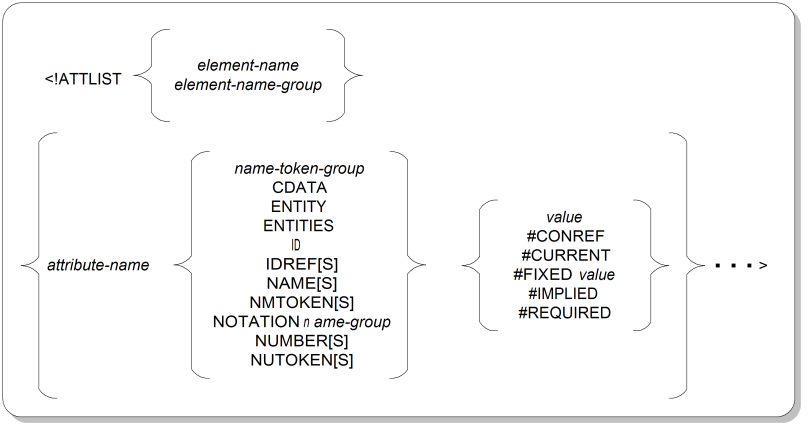
Figure A.2, “Attribute Definition List Declaration Syntax” shows the syntax for attribute definition list declarations.
ATTLISTKeyword that starts an element's attribute list declaration. Only one attribute list declaration can be provided for any one element. (Attribute lists can be associated with data content notations as well as with elements.)
element-name, element-name-groupThe one or more element names whose attribute list is being declared. If more than one element is supplied, the group must be surrounded by parentheses. Its components can be separated using any connector.
<!ATTLIST elem ...>
<!ATTLIST (elem1|elem2) ...>
attribute-nameThe name of the attribute being declared by the specification that follows.
<!ATTLIST elem
att1 ...
att2 ...
>
Any number of attributes can be declared.
name-token-groupA series of one or more strings of characters out of which the attribute value must be chosen, if it must be supplied at all. The group must be surrounded by parentheses. If more than one string is supplied, the strings can be separated using any connector. If the strings contain characters other than those allowed in SGML NAME values, each string must be surrounded with quotation marks.
<!ATTLIST elem
att (val1|val2) ...
>
The same declared-value token can't be repeated in multiple token groups in the same attribute list declaration. The keyword values for the declared value are explained in Table A.1, “Attribute Declared Values”.
valueA default value for the attribute that consists of a string of characters. If the string contains characters other than those allowed in SGML NAME values, it must be surrounded with quotation marks.
<!ATTLIST elem
att (val1|val2) val1
>
Only attributes with the declared value CDATA can have a default value consisting of an empty string ("").
The keyword values for the default value are explained in Table A.2, “Attribute Default Values”.
Table A.1, “Attribute Declared Values” summarizes the rules for
attribute declared values. While the examples of attribute values here are shown in double quotation marks ( " ), it is possible to leave off the quotation marks if the value is allowed to contain NAME characters and the actual value contains only NAME characters (even if the string is longer than NAMELEN ). Also, single quotation marks ( ' ) can be used instead of double ones. If the string must itself contain quotation
marks of one kind, use marks of the other kind to quote the string.
Table A.1. Attribute Declared Values
| Declared Value | Lexical Constraints | Description |
|---|---|---|
CDATA |
Case sensitive. Maximum length: All characters: any valid SGML data character. |
Free-form string of character data. If string contains any character not allowed in Only attributes with the declared value Examples (assuming an attribute that contains translation instructions): Right: Wrong: |
ENTITY |
Case sensitive. Maximum length: First character: A..Z, a..z. Subsequent characters: A..Z, a..z, 0..9, period, hyphen. |
Reference to an entity name declared in the document, which can represent the current element's “content.” Do not supply the entity reference delimiters ( Examples: Right: Wrong: |
ENTITIES |
Case sensitive. Maximum length: First character: A..Z, a..z. Subsequent characters: A..Z, a..z, 0..9, period, hyphen. |
References to one or more entity names declared in the document, separated by spaces. Do not supply the entity reference delimiters ( If more than one entity reference is supplied, surround the entire collection with quotes. Examples: Right: Wrong: |
ID |
Case insensitive. Maximum length: First character: A..Z. Subsequent characters: A..Z, 0..9, period, hyphen. |
Symbolic identifier to be associated with the element. Each value must be unique in the document instance. An attribute with the declared value By convention, The default value for an Examples: Right: Wrong: |
IDREF |
Case insensitive. Maximum length: First character: A..Z. Subsequent characters: A..Z, 0..9, period, hyphen. |
Reference to an element's symbolic identifier in the current document instance. Examples: Right: Wrong: |
IDREFS |
Case insensitive. Maximum length: First character: A..Z. Subsequent characters: A..Z, 0..9, period, hyphen. |
Series of one or more references to element symbolic identifiers in the current document instance, separated by spaces. If more than one ID reference is supplied, surround the entire collection with quotes. Examples: Right: Wrong: |
NAME |
Case insensitive. Maximum length: First character: A..Z. Subsequent characters: A..Z, 0..9, period, hyphen. |
Name string that can be used as an application-specific keyword. Examples: Right: Wrong: |
NAMES |
Case insensitive. Maximum length: First character: A..Z. Subsequent characters: A..Z, 0..9, period, hyphen. |
Series of one or more name strings, separated by spaces. If more than one name string is supplied, surround the entire collection with quotes. Examples: Right: Wrong: |
NMTOKEN |
Case insensitive. Maximum length: All characters: A..Z, 0..9, period, hyphen. |
Name string with relaxed first-character rules. Examples: Right: Wrong: |
NMTOKENS |
Case insensitive. Maximum length: All characters: A..Z, 0..9, period, hyphen. |
Series of one or more name strings with relaxed first-character rules, separated by spaces. If more than one name string is supplied, surround the entire collection with quotes. Examples: Right: Wrong: |
NOTATION |
Case insensitive. Maximum length: First character: A..Z. Subsequent characters: A..Z, 0..9, period, hyphen. |
Reference to a notation name declared in the document, indicating the data content notation of the current element. The An attribute with the declared value Examples: Right: Wrong: |
NUMBER |
Case insensitive. Maximum length: All characters: 0..9. |
Whole-number string. Examples: Right: Wrong: |
NUMBERS |
Case insensitive. Maximum length: All characters: 0..9. |
Series of one or more whole-number strings, separated by spaces. If more than one number is supplied, surround the entire collection with quotes. Examples: Right: Wrong: |
NUTOKEN |
Case insensitive. Maximum length: First character: 0..9. Subsequent characters: A..Z, 0..9, period, hyphen. |
Number string with relaxed subsequent-character rules. Examples: Right: Wrong: |
NUTOKENS |
Case insensitive. Maximum length: First character: 0..9. Subsequent characters: A..Z, 0..9, period, hyphen. |
Series of one or more number strings with relaxed subsequent-character rules, separated by spaces. If more than one number is supplied, surround the entire collection with quotes. Examples: Right: Wrong: |
Table A.2, “Attribute Default Values” summarizes the rules for attribute default values.
Table A.2. Attribute Default Values
| Default Value | Description |
|---|---|
#CONREF |
It is optional to supply a value for this attribute. If it is supplied, however, the element cannot have any content and cannot have an end-tag, as if the element were declared to be The attribute value is usually assumed to provide information that enables retrieval of the element “content,” such as an entity reference. This default value cannot be used if the element requires content or if the element has a declared value of |
#CURRENT |
The value most recently supplied for this attribute on an element of the same type will be used as the default for the current element. “Recent” means found before this element in the linear stream of document data. The first occurrence of the element must specify a value for this attribute. |
#FIXED " |
The value that follows is the only possible value for the attribute, and it is provided as a default. |
#IMPLIED |
It is optional to supply a value for this attribute in the document instance; applications will need to supply their own value if one is needed for processing. Attributes with a declared value of |
#REQUIRED |
A value must be supplied for the attribute in the document instance. Attributes with a declared value of |
Following are the SGML declaration quantities related to attributes.
The total number of name tokens, including attribute names, in the attribute definition list portion of any one attribute list declaration cannot exceed ATTCNT, which is 40 in the reference quantity set.
The number of characters in an element start-tag's attribute specifications list cannot exceed ATTSPLEN, which is 960 in the reference quantity set.
The number of characters in any one attribute value cannot exceed LITLEN, which is 240 in the reference quantity set.
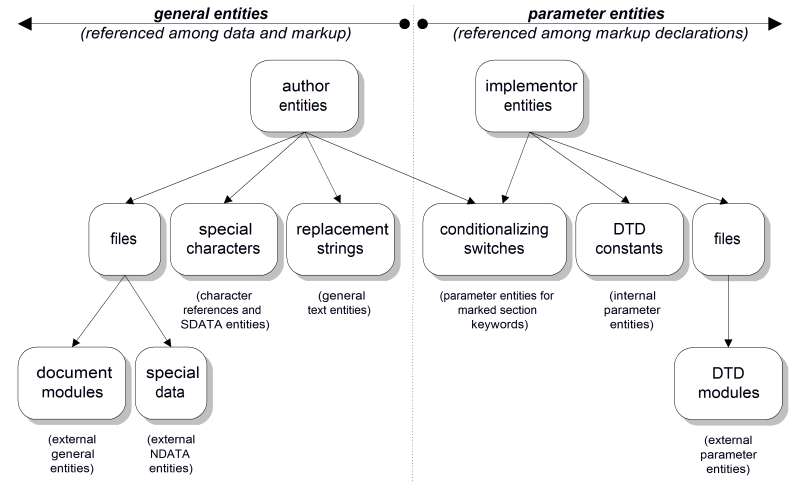
Figure A.3, “Functional Entity Types” shows the relationships between the functional categories of entity available to to be referenced by authors and DTD implementors, and gives the SGML name for the kind of entity usually used for each.
Following are the SGML declaration quantities related to entities.
The number of characters in an entity name cannot exceed NAMELEN , which is 8 in the reference quantity set. For parameter entities, the percent sign ( % ) delimiter must be counted as part of the name.
The number of characters in a quoted value supplied in an entity declaration cannot exceed LITLEN, which is 240 in the reference quantity set. If the value is preceded by one of the keywords STARTTAG, ENDTAG, MS, or MD, the SGML markup delimiters for those constructs must be counted as part of the value.
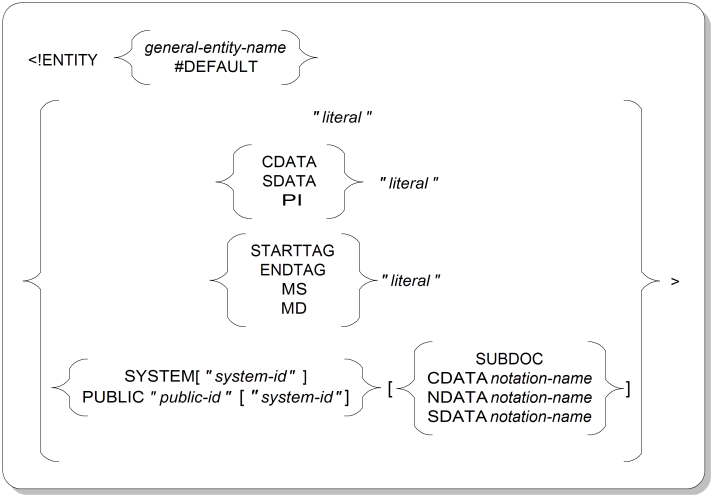
General entities are used in document data and markup. Figure A.4, “General Entity Declaration Syntax” shows the syntax for general entity declarations.
ENTITYKeyword that starts an entity declaration.
general-entity-nameThe name of the general entity being declared.
<!ENTITY ent ...>
#DEFAULTKeyword indicating that the declaration is for the “default” entity, which will be used whenever an entity is referenced that has not been explicited declared.
<!ENTITY #DEFAULT ...>
literalA quoted string containing data and possibly SGML markup that serves as the replacement string for this entity when it is referenced. If it contains markup, the markup should be balanced; that is, it should close any elements it opens.
<!ENTITY ent "text">
The ISO name for this is an internal entity specification.
CDATA "literal"Keyword indicating that the entity's replacement string is to be treated as CDATA, that is, that entity references and element markup won't be recognized. The ISO name for this is an internal entity specification with data text.
<!ENTITY ent CDATA "chars">
SDATA "literal"Keyword indicating that the entity's replacement string is “system-specific” data containing instructions that are nonportable across computer systems. Typically, SDATA entities are used for special characters and symbols. This is an internal entity specification with data text.
<!ENTITY ent SDATA "instrucs">
PI "literal"Keyword indicating that the entity's replacement string should be treated as a processing instruction. The ISO name for this is an internal entity specification with data text.
<!ENTITY ent PI "instrucs">
STARTTAG "literal"Keyword indicating that the entity's replacement string should be interpreted as having start-tag delimiters around it, so that it can function as start-tag markup: <.literal>
<!ENTITY ent STARTTAG "elemname att="value">
Using the STARTTAG keyword rather than including the delimiters directly in the replacement string is helpful for protecting against changes to the concrete syntax in which SGML markup is expressed.
The ISO name for this is an internal entity specification with bracketed text.
ENDTAG "literal"Keyword indicating that the entity's replacement string should be interpreted as having end-tag delimiters around it, so that it can function as end-tag markup: </.literal>
<!ENTITY ent ENDTAG "elemname">
Using the ENDTAG keyword rather than including the delimiters directly in the replacement string is helpful for protecting against changes to the concrete syntax in which SGML markup is expressed.
The ISO name for this is an internal entity specification with bracketed text.
MS "literal"Keyword indicating that the entity's replacement string should be interpreted as having marked section delimiters around it, so that it can function as a marked section region: <![ .literal]]>
<!ENTITY ent MS "IGNORE [ignored-stuff">
Using the MS keyword rather than including the delimiters directly in the replacement string may not help protect against changes to the concrete syntax in which SGML markup is expressed, because the literal must actually contain the inner opening square bracket (or alternate character, if you have redefined the concrete syntax).
The ISO name for this is an internal entity specification with bracketed text.
MD "literal"Keyword indicating that the entity's replacement string should be interpreted as having markup declaration delimiters around it, so that it can function as a markup declaration: <! .literal>
<!ENTITY ent MD "--cmt--">
Using the MD keyword rather than including the delimiters directly in the replacement string is helpful for protecting against changes to the concrete syntax in which SGML markup is expressed.
The ISO name for this is an internal entity specification with bracketed text.
SYSTEMKeyword indicating that the entity's contents can be found on a computer system, stored separately from the entity declaration.
<!ENTITY ent SYSTEM>
system-idA file name, pathname, or other specification for how to locate the entity content on the computer system.
<!ENTITY ent SYSTEM "file.sgm">
PUBLICKeyword indicating that the entity's contents can be found on a computer system and that the contents can be located by mapping the supplied public identifier to location instructions that are stored outside the SGML document. An entity with a public identifer can also optionally have system location instructions stored with it.
<!ENTITY ent PUBLIC "logical-name">
public-idSymbolic identifier that maps to location instructions. The mapping is done by an entity manager, often through the use of a catalog file that lists public IDs and their corresponding physical locations.
If the FORMAL feature is set to YES in the SGML declaration, the public identifier must be constructed according to certain syntactic rules, described in Section A.10, “Formal Public Identifiers and Catalogs”.
SUBDOCKeyword indicating that the entity contents are considered to be a separate SGML document, with its own DOCTYPE declaration pointing to a potentially different DTD.
<!ENTITY ent SYSTEM SUBDOC>
The SUBDOC keyword can be used only if the SUBDOC feature in the SGML declaration is set to YES.
If an entity type of SUBDOC, CDATA, NDATA, or SDATA is not specified, the entity is assumed to contain SGML text and markup.
CDATA notation-nameKeyword indicating that the entity contents are to be treated as CDATA, that is, that entity references and element markup won't be recognized. The notation must have been declared in a NOTATION declaration.
<!ENTITY ent SYSTEM CDATA notn>
If an entity type of SUBDOC, CDATA, NDATA, or SDATA is not specified, the entity is assumed to contain SGML text and markup.
NDATA notation-nameKeyword and value indicating that the entity contents are to be treated as non-SGML data of the specified notation. The notation must have been declared in a NOTATION declaration.
<!ENTITY ent SYSTEM NDATA notn>
If an entity type of SUBDOC, CDATA, NDATA, or SDATA is not specified, the entity is assumed to contain SGML text and markup.
SDATA notation-nameKeyword indicating that the entity contents consist of data that is “system-specific”, that is, nonportable across computer systems. The notation must have been declared in a NOTATION declaration.
<!ENTITY ent SYSTEM SDATA notn>
If an entity type of SUBDOC, CDATA, NDATA, or SDATA is not specified, the entity is assumed to contain SGML text and markup.
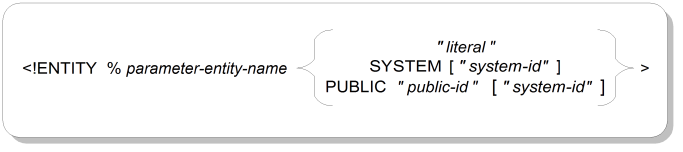
Parameter entities are used in markup declarations. Figure A.5, “Parameter Entity Declaration Syntax” shows the syntax for parameter entity declarations.
ENTITYKeyword that starts an entity declaration.
%Key letter that indicates that the declaration is for a parameter entity, an entity that can be referenced only within markup declarations. The percent sign must be surrounded by spaces.
parameter-entity-nameThe name of the parameter entity.
<!ENTITY % ent ...>
literalA quoted string containing replacement data for the parameter entity.
<!ENTITY % ent "string">
SYSTEMKeyword indicating that the entity's contents can be found on a computer system, stored separately from the entity declaration.
<!ENTITY % ent SYSTEM>
system-idA file name, pathname, or other specification for how to locate the entity contents on the computer system.
<!ENTITY % ent SYSTEM "file.dtd">
PUBLICKeyword indicating that the entity's contents can be found on a computer system and that the contents can be located by mapping the supplied public identifier to location instructions that are stored outside the SGML document. An entity with a public identifer can also optionally have system location instructions stored with it.
<!ENTITY % ent PUBLIC "logical-name">
public-idSymbolic identifier that maps to location instructions. The mapping is done by an entity manager, often through the use of a catalog file that lists public IDs and their corresponding physical locations.
If the FORMAL feature is set to YES in the SGML declaration, the public identifier must be constructed according to certain syntactic rules, described in Section A.10, “Formal Public Identifiers and Catalogs”.
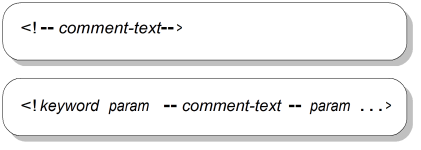
Figure A.6, “Comment Syntax” shows the syntax for comment declarations and comments interspersed within other markup declarations. Note that comment declarations and marked section declarations are the only kinds of markup declarations that can appear directly in a document instance.
For example:
<!DOCTYPE doc [
<!-- Here is the document element's definition.
This document type isn't actually good for much.
-->
<!ELEMENT doc - - (front, body)>
<!ATTLIST doc id ID #REQUIRED
<!ELEMENT front - - (title) --front is for metainfo-->
<!ELEMENT title - - (#PCDATA)>
<!ELEMENT body - - (para+)>
<!ELEMENT para - - (#PCDATA)>
]>
<doc id="a-small-doc">
<front><title>This Is a Title<!--check: is this
an acceptable title?--></title>
<body>
<para>
The first paragraph.
</para>
<para>
A second paragraph.
</para>
</body>
</doc>
Comments can be placed inside other markup declarations in most locations where white space must appear. However, they cannot be placed inside a content model group in an element declaration (though they can appear between a content model group and any exceptions, and between exclusions and inclusions). Whole comment declarations can be placed almost anywhere within a document instance, but can't appear inside start-tags, end-tags, or other markup.
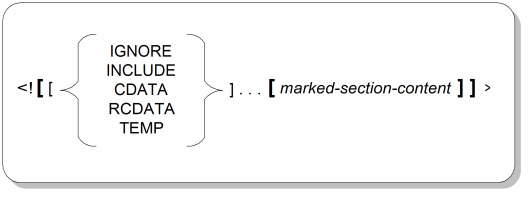
Marked sections are delimited regions of document content that should receive special attention by the parser. Each marked section is actually a markup declaration, one of only two kinds that can appear directly in a document instance (the other kind is a comment declaration). Figure A.7, “Marked Declaration Syntax” shows the syntax for marked section declarations. Note that square brackets that are actually part of the SGML markup are shown in boldface, whereas brackets used to indicate the optionality of a field are not given emphasis.
IGNOREKeyword indicating that the characters in the region, other than the ones ending the marked section, should go unrecognized by parsers.
<![ IGNORE [...]]>
Often, this status keyword is stored in a parameter entity and referred to indirectly in the marked section.
INCLUDEKeyword indicating that the characters in the region should be treated by parsers as providing document content.
<![ INCLUDE [...]]>
Often, this status keyword is stored in a parameter entity and referred to indirectly in the marked section.
CDATAKeyword indicating that any characters in the region, other than the characters that end the marked section, should be interpreted not as markup or markup delimiters but as ordinary document data.
<![ CDATA [...]]>
Note that the characters ]]> cannot appear in the content of CDATA marked section because they will be interpreted as the end of the marked section.
RCDATAKeyword indicating that the only kind of markup that should be recognized in the region, other than the ones ending the marked section, are entity references.
<![ RCDATA [...]]>
Note that the characters ]]> cannot appear in the content of RCDATA marked section because they will be interpreted as the end of the marked section.
TEMPKeyword indicating that the content of the region is only temporarily being provided as part of the document content.
<![ TEMP [...]]>
marked-section-contentValid SGML characters making up the content of the region.
The prize includes <![ %mice-only; [a lifetime supply of cheese and ]]> a cruise to the Bahamas.
If no keyword is supplied, INCLUDE is assumed. If multiple status keywords are supplied, they are given the following priority:
IGNORE
CDATA
RCDATA
INCLUDE
It is possible to nest marked sections, except inside CDATA and RCDATA sections, where the start of the inner marked section will be ignored and treated as ordinary data content, and the end of the inner marked section will terminate the outer marked section.
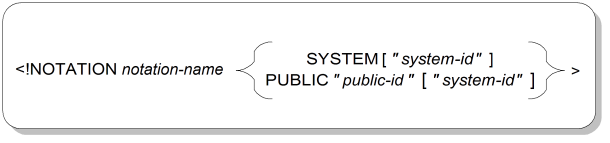
A data notation is a descriptor for data that is in non-SGML form and therefore should be handed off by a parser to some other processor. The notation helps to identify the alternate processing that would be appropriate for the data. Figure A.8, “Notation Declaration Syntax” shows the syntax for data notation declarations. The external identifier is intended to identify a “document” that specifies the particulars of the notation, which may be simply a descriptive string.
NOTATIONKeyword that starts a notation declaration.
notation-nameThe name of the notation.
<!NOTATION eps ...>
SYSTEMKeyword indicating that the document that specifies the notation can be found on a computer system, stored separately from the entity declaration.
<!NOTATION eps SYSTEM>
system-idA file name, pathname, or other specification for how to locate the document that specifies the notation on the computer system.
<!NOTATION eps SYSTEM "eps.doc">
PUBLICKeyword indicating that the document that specifies the notation can be found on a computer system and that the contents can be located by mapping the supplied public identifier to location instructions that are stored outside the SGML document. A notation document with a public identifer can also optionally have system location instructions stored with it.
<!NOTATION eps PUBLIC "+//ISBN 0-201-18127-4::Adobe//NOTATION PostScript Language Ref. Manual//EN">
Many common non-SGML notations have formal public identifiers associated with them. A formal public identifier for a notation should use the NOTATION keyword.
public-idSymbolic identifier that maps to location instructions. The mapping is done by an entity manager, often through the use of a catalog file that lists public IDs and their corresponding physical locations.
If the FORMAL feature is set to YES in the SGML declaration, the public identifier must be constructed according to certain syntactic rules, described in Section A.10, “Formal Public Identifiers and Catalogs”.
A processing instruction provides instructions to a processing application or system for how the SGML document is to be handled. Often, processing instructions are explicitly procedural. Figure A.9, “Processing Instruction Syntax” shows the syntax for processing instructions.
processing-instructionString intended for interpretation by a system or application besides the parser.
<?MyApp break-line-here>
The document type declaration is the means by which an SGML document indicates the DTD rules to which it conforms. Figure A.10, “Document Type Declaration Syntax” shows the syntax for document type declarations. Note that square brackets that are actually part of the SGML markup are shown in boldface, whereas brackets used to indicate the optionality of a field are not given emphasis. Note also that after the document type name, at least one of the two fields must appear: an external identifier, actual markup declarations, or both.
DOCTYPEKeyword that starts a document type declaration.
doctype-nameThe name of the document type. This must be the same as the name of the document element (the top-level element).
<!DOCTYPE loveltr ...>
SYSTEMKeyword indicating that the collection of some or all of the DTD's markup declarations can be found on a computer system, stored separately from the document type declaration.
<!DOCTYPE loveltr SYSTEM>
system-idA file name, pathname, or other specification for how to locate some or all of the DTD's markup declarations on the computer system.
<!DOCTYPE loveltr SYSTEM "loveltr.doc">
PUBLICKeyword indicating that some or all of the DTD's markup declarations can be found on a computer system and that the contents can be located by mapping the supplied public identifier to location instructions that are stored outside the SGML document. A DTD with a public identifer can also optionally have system location instructions stored with it.
<!DOCTYPE loveltr PUBLIC "-//Elvis Chapel//DTD Love Letter//EN">
public-idSymbolic identifier that maps to location instructions. The mapping is done by an entity manager, often through the use of a catalog file that lists public IDs and their corresponding physical locations.
If the FORMAL feature is set to YES in the SGML declaration, the public identifier must be constructed according to certain syntactic rules, described in Section A.10, “Formal Public Identifiers and Catalogs”.
markup-declarationsThe internal subset of markup declarations, which can represent either all the necessary declarations to make a complete DTD, or a set of declarations that complement those found in a remote location. Supplying an internal subset is optional if an external identifier has been provided.
The SGML declaration specifies setup instructions to SGML parsers and to humans. For example, it indicates the character set and the optional SGML features used in a document. If it is present, it appears in an SGML document before the document type declaration and the actual data and markup making up the document instance. (Note that it cannot be included by means of an entity reference, though some parsers allow a separate file containing an SGML declaration to be read in separately from files containing the rest of the document.) If the SGML declaration is absent, each system assumes some set of default specifications.
An SGML declaration contains a series of parameters specifying various characteristics of the DTD and instance that follow. Figure A.11, “SGML Declaration Syntax” shows the order of the parameters.
SGMLKeyword that starts an SGML declaration.
8879:yearThe version of the standard being referenced. To date, 1986 (the year of the standard's publication) is the only value that is valid in year.
Note that the original ISO 8879 standard specified its own name to be ISO 8879-1986, with a hyphen ( - ) separating the two parts of the identifier. Amendment 1 to the standard changed the hyphen to a colon ( : ) to make it conform to the naming scheme used by other ISO standards. Some SGML systems accept only one character or the other, depending on when they were developed and how flexible they are. The SGML Open organization has issued Technical Resolution 9401, which specifies in part that systems should be flexible enough to accept either the hyphen or the colon in formal public identifiers.
document-character-setDescription of how the codes representing data characters in the document are to be interpreted as logical characters. The document character set parameter is discussed in Section A.9.1, “Document Character Set”.
capacity-setDeclaration of the approximate computer storage capacity needed by systems to process the DTD and document instance. The capacity set parameter is discussed in Section A.9.2, “Capacity Set”.
concrete-syntax-scopeIndication of which parts of the SGML document adhere to the reference concrete syntax, and which to any variant concrete syntax defined. The concrete syntax scope parameter is discussed in Section A.9.3, “Concrete Syntax Scope”.
concrete-syntaxSpecification of the “concrete” (literal) characteristics of the markup used in this document, as opposed to the abstract characteristics specified by the SGML standard. This is the most complex section of the SGML declaration. The concrete syntax parameter is discussed in Section A.9.4, “Concrete Syntax”.
feature-useSpecification of the optional SGML features that this document uses. The feature use parameter is discussed in Section A.9.5, “Feature Use”.
application-specific-infoInformation that needs to be communicated to processors that does not appear in the document or its DTD. Documents that use HyTime and ICADD (the International Committee for Accessible Document Design) are expected to supply information here. The application-specific information parameter is discussed in Section A.9.6, “Application-Specific Information”.
Example A.1, “Sample SGML Declaration” shows an example of an SGML declaration that uses most of the syntactic features available in the parameters; the declaration happens to be the one used for this book. There is no one “default SGML declaration,” but certain collections of default values and settings are used to define conformance levels of SGML documents to the standard:
The following sections explain these default values.
Example A.1. Sample SGML Declaration
<!SGML "ISO 8879:1986"
CHARSET
BASESET
"ISO 646:1983//CHARSET International Reference Version (IRV)//ESC 2/5 4/0"
DESCSET
0 9 UNUSED
9 2 9
11 2 UNUSED
13 1 13
14 18 UNUSED
32 95 32
127 1 UNUSED
BASESET
"ISO Registration Number 100//CHARSET ECMA-94 Right Part of Latin Alphabet
Nr. 1//ESC 2/13 4/1"
DESCSET
128 32 UNUSED
160 96 32
CAPACITY SGMLREF
TOTALCAP 500000
ATTCAP 70000
ATTCHCAP 35000
AVGRPCAP 35000
ELEMCAP 35000
ENTCAP 70000
ENTCHCAP 35000
GRPCAP 300000
IDCAP 35000
IDREFCAP 35000
SCOPE DOCUMENT
SYNTAX
SHUNCHAR CONTROLS 0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19
20 21 22 23 24 25 26 27 28 29
30 31 127 128 129
130 131 132 133 134 135 136 137 138 139
140 141 142 143 144 145 146 147 148 149
150 151 152 153 154 155 156 157 158 159
BASESET "ISO 646:1983//CHARSET
International Reference Version (IRV)//ESC 2/5 4/0"
DESCSET
0 128 0
FUNCTION
RE 13
RS 10
SPACE 32
TAB SEPCHAR 9
NAMING
LCNMSTRT ""
UCNMSTRT ""
LCNMCHAR ".-"
UCNMCHAR ".-"
NAMECASE
GENERAL YES
ENTITY NO
DELIM
GENERAL SGMLREF
SHORTREF SGMLREF
NAMES SGMLREF
QUANTITY SGMLREF
ATTCNT 256
GRPCNT 253
GRPGTCNT 253
LITLEN 8092
NAMELEN 44
TAGLVL 100
FEATURES
MINIMIZE
DATATAG NO
OMITTAG NO
RANK NO
SHORTTAG YES
LINK
SIMPLE NO
IMPLICIT NO
EXPLICIT NO
OTHER
CONCUR NO
SUBDOC NO
FORMAL YES
APPINFO NONE
>
The SGML declaration can specify an alternative to the reference concrete syntax, the default set of markup delimiters and other markup characteristics that SGML assumes. (Changing the default is discussed in Section A.9.4, “Concrete Syntax”.) For example, you can specify that curly braces should be used instead of angle brackets in markup declarations and tags. If a variant concrete syntax is defined, however, the SGML declaration itself must still use the defaults.
Within the SGML declaration, no entity references can be used except for numeric character references, since the declaration's position in a document is before the point where any normal entities can have been defined. Several parameters in the SGML declaration allow or require specification of a public identifier corresponding to an external entity, but these entities do not need to be declared in the normal way.
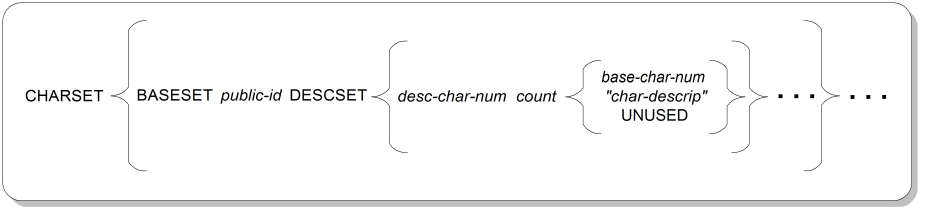
The document character set parameter contains instructions on how to interpret the numeric codes stored electronically in an SGML document as characters. Figure A.12, “CHARSET Parameter Syntax” shows the syntax for the document character set parameter.
CHARSETKeyword for the character set parameter. This parameter is meant for human consumption. Parsers have a “bootstrapping” problem in using the CHARSET parameter to parse SGML declarations; because an SGML declaration itself is stored electronically, parsers must use a “default” understanding of the character codes within in order to read the declaration in the first place.
BASESETKeyword introducing the public identifier of a well-known repertoire of logical characters to which to map the actual character codes found in the document. For example, “the ABC's” is a well-known character repertoire, and it might be commonly understood to be represented by the numbers 0 to 25.
Multiple BASESET/DESCSET pairs can appear here.
public-idSymbolic identifier that maps to a description of a character repertoire and the numeric codes representing those characters. The mapping is done by an entity manager, often through the use of a catalog file that lists public IDs and their corresponding physical locations.
If the FORMAL feature is set to YES in the SGML declaration (see Section A.9.5, “Feature Use”), the public identifier must be constructed according to certain syntactic rules, described in Section A.10, “Formal Public Identifiers and Catalogs”.
DESCSETKeyword introducing the “described character set,” a succession of three-field entries explaining how the numeric codes found in this document should be interpreted to map to the characters represented by the base character set provided above.
The simplest example might be a case where ISO 646 is both the base character set and the set actually used in the document:
DESCSET 0 128 0
desc-char-numNumeric character code that might be found in the document.
If the count field is greater than 1, this field serves as a starting point for a contiguous series of numeric codes corresponding to a contiguous series of the same length in the base character set.
countThe number of codes, counting upwards, in succession that map exactly between the described and base character sets.
If the number is 1, there is a simple mapping between the described code and the base code. If the number is greater than 1, a contiguous series of described codes corresponds to a contiguous series of the same length of base codes.
base-char-numNumeric character code in the base character set that is associated with a logical character. For example, in ISO 646, the number 65 represents the letter A.
If the count field is greater than 1, this field serves as a starting point for a contiguous series of numeric codes corresponding to a contiguous series of the same length in the described character set.
"char-descrip"Prose description of the logical character intended to be represented, for example, “happy face.” Such a description might need to be used if the character set used in the document needs characters not contained in the base character set.
UNUSEDIndicator that this numeric code should not be found in the document. Such a code is considered a non-SGML character and is not allowed to appear in the document.
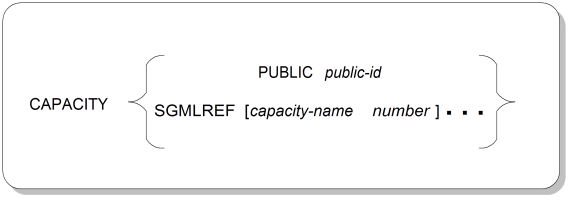
The capacity set parameter defines the maximum number of occurrences of various constructs in an SGML document, measured in terms of the number of points (characters) needed to store information about them. Many of the capacities are related to DTDs and thus will reflect requirements that don't change from document to document, but some are related to information found in a particular document instance. Figure A.13, “CAPACITY Parameter Syntax” shows the syntax for the capacity set parameter.
CAPACITYKeyword for the capacity set parameter.
PUBLICKeyword indicating that what follows is a public identifier for an externally stored collection of capacity settings.
public-idSymbolic identifier that maps to a collection of capacity settings. The mapping is done by an entity manager, often through the use of a catalog file that lists public IDs and their corresponding physical locations.
If the FORMAL feature is set to YES in the SGML declaration (see Section A.9.5, “Feature Use”), the public identifier must be constructed according to certain syntactic rules, described in Section A.10, “Formal Public Identifiers and Catalogs”.
SGMLREFKeyword indicating that the reference capacity set should be used, except for any capacities provided below. The reference capacity set is explained in Table A.3, “Reference Capacity Set”.
capacity-nameKeyword indicating the capacity whose maximum is being set. The available capacity categories are listed in Table A.3, “Reference Capacity Set”.
numberThe maximum number of computer storage points for the indicated capacity category that this SGML document needs. The default capacity points provided by the reference capacity set are listed in Table A.3, “Reference Capacity Set”.
Table A.3, “Reference Capacity Set” lists the available capacity categories and their reference point values and explains how the number of points is derived in each case.
Table A.3. Reference Capacity Set
| Capacity | Points | Description and Point Calculation |
|---|---|---|
TOTALCAP |
35000 |
The total number of points required. |
ENTCAP |
35000 |
The number of entities declared, multiplied by |
ENTCHCAP |
35000 |
The number of characters in text entities declared. |
ELEMCAP |
35000 |
The number of elements declared, multiplied by |
GRPCAP |
35000 |
The number of model groups, elements, data tag groups, and reserved name keywords (such as |
EXGRPCAP |
35000 |
The number of exception (exclusion and inclusion) groups mentioned in element declarations, multiplied by |
EXNMCAP |
35000 |
The number of names mentioned in exception (exclusion and inclusion) groups in element declarations, multiplied by |
ATTCAP |
35000 |
The number of attributes that are declared in attribute definition list declarations, plus the number of attributes that occur in link set declarations, plus the number of notation names associated with entity declarations, multiplied by |
ATTCHCAP |
35000 |
The number of characters in attribute default values, plus the number of characters explicitly specified in link set declarations and data attribute specifications. |
AVGRPCAP |
35000 |
The number of tokens defined in the name or name token groups for attribute declared values, multiplied by |
NOTCAP |
35000 |
The number of data content notations declared, multiplied by |
NOTCHCAP |
35000 |
The number of characters in notation external identifiers. |
IDCAP |
35000 |
The number of attributes with a declared type of |
IDREFCAP |
35000 |
The number of attributes with a declared type of |
MAPCAP |
35000 |
The number of short reference maps declared, plus the number of short reference delimiters in the concrete syntax multiplied by the number of maps, with the whole multiplied by |
LKSETCAP |
35000 |
The number of link types and link sets defined, multiplied by |
LKNMCAP |
35000 |
The number of document types or elements in a link type or link set declaration, multiplied by |
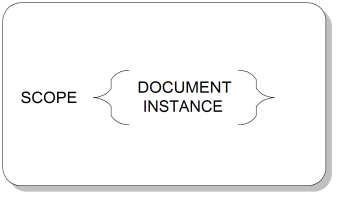
The concrete syntax scope parameter declares which parts of the document use the reference concrete syntax and which use a variant concrete syntax. If the reference concrete syntax is being used for the document instance, this parameter has no effect. Figure A.14, “SCOPE Parameter Syntax” shows the syntax for the concrete syntax scope parameter.
SCOPEKeyword for the concrete syntax scope parameter.
DOCUMENTKeyword indicating that the concrete syntax defined in the SGML declaration is used everywhere in the document (except for the SGML declaration itself), including both the instance and the prolog (the markup declarations making up the one or more DTD and any link set declarations).
INSTANCEKeyword indicating that the concrete syntax defined in the SGML declaration is used only in the document instance, with the reference concrete syntax being used in the prolog. There are some restrictions on the variant concrete syntax if this keyword is specified, relating to ensuring that parsers can properly distinguish between the prolog and the instance and can handle both syntaxes.
The SGML standard defines many characteristics of SGML markup in terms of an abstract syntax, for example, defining the ways that a “start tag open” or STAGO delimiter is used, and defining its default concrete representation separately as a left angle bracket ( < ). In this way, you can change the actual characters and keywords used for SGML markup if you need to.
The concrete syntax parameter specifies such particulars of the markup used in the document (or just in the document instance, if the scope has been defined this way; see Section A.9.3, “Concrete Syntax Scope” for more information).
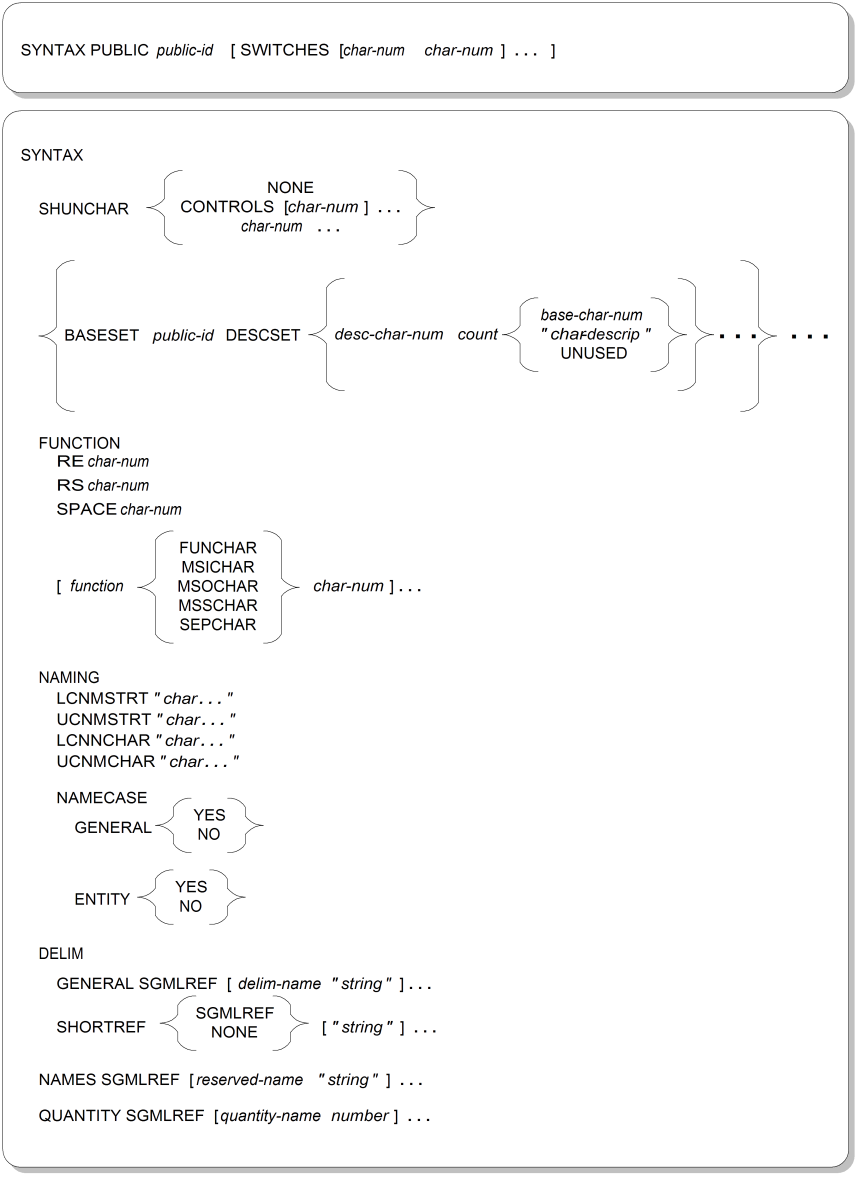
Figure A.15, “SYNTAX Parameter Syntax” shows the syntax for the concrete syntax parameter. To specify a concrete syntax that is defined externally to the SGML declaration, use the first form. To specify the individual characteristics of a concrete syntax, use the second form.
SYNTAXKeyword for the concrete syntax parameter.
PUBLICKeyword indicating that what follows is a public identifier for an externally stored description of a concrete syntax.
public-idSymbolic identifier that maps to a description of a concrete syntax. The mapping is done by an entity manager, often through the use of a catalog file that lists public IDs and their corresponding physical locations.
If the FORMAL feature is set to YES in the SGML declaration (see Section A.9.5, “Feature Use”), the public identifier must be constructed according to certain syntactic rules, described in Section A.10, “Formal Public Identifiers and Catalogs”.
SWITCHES etc.Specification of pairs of character numbers whose logical meanings should be switched. This parameter allows a concrete syntax identified by a public ID to be used with only slight changes. An example of characters that might need to be switched is the line feed and carriage return characters, numbers 10 and 13 in the character set used by the reference concrete syntax.
SHUNCHAR etc.Indication of the characters that should be prohibited from being used in markup (as opposed to data). The NONE keyword means that no characters are shunned. The CONTROLS keyword means that all “control characters” (as opposed to graphic characters) should be shunned. Any individual character numbers specified
will be shunned as well.
BASESET etc.Specification of the “syntax-reference character set,” the mapping of numeric character codes used in markup to logical character meanings for the purpose of this subparameter. Its presence allows all specifications of character numbers and numeric character entity references in the SYNTAX parameter to be independent of the character set specified for data content in CHARSET.
See Figure A.12, “CHARSET Parameter Syntax” for a description of how to supply BASESET/CHARSET information.
FUNCTION etc.Specification of the character numbers that correspond to special function character roles in SGML markup. RE identifies the record end character, RS identifies the record start character, and SPACE identifies the space character. Additional character
numbers can be named and assigned special function roles as follows:
FUNCHAR names and identifies characters that have a system-specific function unrelated to SGML. Once defined in this way, such function character names can be used in character entity references (&#).name
MSOCHAR names and identifies characters that inhibit markup recognition from the point where they appear.
MSICHAR names and identifies characters that re-enable markup recognition from the point where they appear.
MSSCHAR names and identifies characters that inhibit markup recognition of the single character that appears after the point where they appear.
SEPCHAR names and identifies separator (white space) characters, such as tabs.
LCNMSTRT etc. in NAMINGDeclaration of the characters that can be used in markup names (such as generic identifiers and entity names). LCNMSTRT and LCNMCHAR specify, respectively, additional lowercase characters that can be in the first position and subsequent positions of a name. UCNMSTRT and UCNMCHAR specify, respectively, the corresponding additional uppercase characters that can be in the first position and the subsequent positions of a name. If a “lowercase” character specified is a symbol that has no case, it should be specified in the same
position in the character list for both the LC and UC fields. Often, an underscore ( _ ) is added to subsequent positions.
If no additional characters are specified, by dfeault the first character must be an uppercase or lowercase letter, and the subsequent characters can be a letter or a digit. The reference concrete syntax adds a period and a hyphen to the subsequent characters. The characters specified here are not raw character numbers; they are either real typed characters or numeric character references.
NAMECASE etc. in NAMINGSetup of the case sensitivity of SGML markup names. GENERAL sets the case sensitivity of all names except for entity names, and ENTITY sets the case sensitivity of entity names. The reference concrete syntax specifies that GENERAL is NO (case insensitive) and ENTITY is YES (case sensitive).
GENERAL etc. in DELIMReplaces the markup delimiters in the reference delimiter set with alternate delimiters. The SGMLREF keyword represents the specification of the reference delimiter set; the delimiter role keywords and their reference delimiters are shown in Table A.4, “Reference General Delimiter Set”.
SHORTREF etc. in DELIMReplaces the short reference markup delimiters in the reference delimiter set with alternate delimiters. The SGMLREF keyword represents the specification of the reference delimiter set (the reference delimiters for short references are not shown here). The NONE keyword means that no short reference delimiters are enabled, except any that are explicitly defined in this SGML declaration.
NAMES etc.Replaces the reserved name keywords in the reference set with alternate keywords. The SGMLREF keyword represents the specification of the reference set; the reference keywords are listed in Table A.5, “Reference Reserved Name Set”. Note that the reserved names from the SGML declaration itself are not listed here, as they must be used in their reference form.
QUANTITY etc.Sets the basic lengths and measurements of various SGML markup characteristics. The SGMLREF keyword represents the specification of the reference quantity set; the quantity keywords and reference values are listed in Table A.6, “Reference Quantity Set”.
Table A.4, “Reference General Delimiter Set” lists the delimiter role keywords and their reference (default) delimiters. You can change these delimiters using the DELIM GENERAL subparameter.
Table A.4. Reference General Delimiter Set
| Delimiter Role Keyword | Reference Delimiter | Description |
|---|---|---|
AND |
& |
And connector |
COM |
- - |
Comment start or end |
CRO |
&# |
Character reference open |
DSC |
] |
Declaration subset close |
DSO |
[ |
Declaration subset open |
DTGC |
] |
Data tag group close |
DTGO |
[ |
Data tag group open |
ERO |
& |
Entity reference open |
ETAGO |
</ |
Eng-tag open |
GRPC |
) |
Group close |
GRPO |
( |
Group open |
LIT |
" |
Literal start or end |
LITA |
' |
Alternative literal start or end |
MDC |
> |
Markup declaration close |
MDO |
<! |
Markup declaration open |
MINUS |
- |
Exclusion |
MSC |
]> |
Marked section close |
NET |
/ |
Null end-tag |
OPT |
? |
Optional occurrence indicator |
OR |
| |
Or connector |
PERO |
% |
Parameter entity reference open |
PIC |
> |
Processing instruction close |
PIO |
<? |
Processing instruction open |
PLUS |
+ |
Required and repeatable occurrence indicator; also inclusion |
REFC |
; |
Reference close |
REP |
* |
Optional and repeatable occurrence indicator |
RNI |
# |
Reserved name indicator |
SEQ |
, |
Sequence connector |
STAGO |
< |
Start-tag open |
TAGC |
> |
Tag close |
VI |
= |
Value indicator |
Table A.5, “Reference Reserved Name Set” lists the reserved name keywords. You can change these keywords using the NAMES subparameter.
Table A.5. Reference Reserved Name Set
ANY |
ATTLIST |
CDATA |
CONREF |
CURRENT |
DEFAULT |
DOCTYPE |
ELEMENT |
EMPTY |
ENDTAG |
ENTITIES |
ENTITY |
FIXED |
ID |
IDLINK |
IDREF |
IDREFS |
IGNORE |
IMPLIED |
INCLUDE |
INITIAL |
LINK |
LINKTYPE |
MD |
MS |
NAME |
NAMES |
NDATA |
NMTOKEN |
NMTOKENS |
NOTATION |
NUMBER |
NUMBERS |
NUTOKEN |
NUTOKENS |
O |
PCDATA |
PI |
POSTLINK |
PUBLIC |
RCDATA |
RE |
REQUIRED |
RESTORE |
RS |
SDATA |
SHORTREF |
SIMPLE |
SPACE |
STARTTAG |
SUBDOC |
SYSTEM |
TEMP |
USELINK |
USEMAP |
Table A.4, “Reference General Delimiter Set” shows the reference quantity set. You can change these quantities using the QUANTITY subparameter.
Table A.6. Reference Quantity Set
| Quantity | Value | Description |
|---|---|---|
ATTCNT |
40 |
The maximum number of attribute names and name tokens (for example, values in a declared value token list) in the attribute definition list of a single attribute declaration. |
ATTSPLEN |
960 |
The maximum number of characters in a start-tag's attribute specifications list, after normalization (for example, to fill in an attribute name that has been omitted through |
BSEQLEN |
960 |
The maximum length of a blank sequence in a short reference string. |
DTAGLEN |
16 |
The maximum length of a data tag. |
DTEMPLEN |
16 |
The maximum length of a data tag template or pattern template. |
ENTLVL |
16 |
The maximum number of levels to which entity references have been nested inside the content of other entities. |
GRPCNT |
32 |
The maximum number of tokens in any one group (for example, a model group or a content model exclusion). |
GRPGTCNT |
96 |
The maximum “grand total” of content tokens (groups, names, and so on) at all levels of a single content model. |
GRPLVL |
16 |
The maximum number of levels to which model groups are nested in a single content model. |
LITLEN |
240 |
The maximum number of characters in a single parameter literal or attribute value literal, not including its delimiters (for example, the length of a |
NAMELEN |
8 |
The maximum number of characters in a markup name or token. |
NORMSEP |
2 |
The value used to represent a “standard” number of separator characters in calculating string lengths that have been normalized. |
PILEN |
240 |
The maximum number of characters in a processing instruction, not including delimiters. |
TAGLEN |
960 |
The maximum number of characters in a start-tag, including all attribute value specification, but not including delimiters. |
TAGLVL |
24 |
The maximum number of levels to which elements can be nested inside other elements in the document instance, or, put another way, the maximum number of elements that can be open at one time. |
You can make use of two ready-made concrete syntaxes defined by the SGML standard, through either a public ID reference or a complete SYNTAX specification. Example A.2, “Reference Concrete Syntax Specification” shows the complete specification for the reference concrete syntax. Its public ID
is as follows:
"ISO 8879:1986//SYNTAX Reference//EN"
Example A.2. Reference Concrete Syntax Specification
SYNTAX
SHUNCHAR CONTROLS 0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19
20 21 22 23 24 25 26 27 28 29
30 31 127 255
BASESET
"ISO 646:1983//CHARSET International Reference Version (IRV)//ESC 2/5 4/0"
DESCSET
0 128 0
FUNCTION
RE 13
RS 10
SPACE 32
TAB SEPCHAR 9
NAMING
LCNMSTRT ""
UCNMSTRT ""
LCNMCHAR ".-"
UCNMCHAR ".-"
NAMECASE
GENERAL YES
ENTITY NO
DELIM
GENERAL SGMLREF
SHORTREF SGMLREF
NAMES SGMLREF
QUANTITY SGMLREF
Example A.3, “Core Concrete Syntax Specification” shows the complete specification for the core concrete syntax, which differs from the reference concrete syntax only in that its SHORTREF delimiters are set to NONE. Its public ID is as follows:
"ISO 8879:1986//SYNTAX Core//EN"
Example A.3. Core Concrete Syntax Specification
SYNTAX
SHUNCHAR CONTROLS 0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17 18 19
20 21 22 23 24 25 26 27 28 29
30 31 127 255
BASESET
"ISO 646:1983//CHARSET International Reference Version (IRV)//ESC 2/5 4/0"
DESCSET
0 128 0
FUNCTION
RE 13
RS 10
SPACE 32
TAB SEPCHAR 9
NAMING
LCNMSTRT ""
UCNMSTRT ""
LCNMCHAR ".-"
UCNMCHAR ".-"
NAMECASE
GENERAL YES
ENTITY NO
DELIM
GENERAL SGMLREF
SHORTREF NONE
NAMES SGMLREF
QUANTITY SGMLREF
This section provides only a brief description of the SYNTAX parameter; see Appendix E, Bibliography and Sources for sources of more detailed information on specifying a concrete syntax.
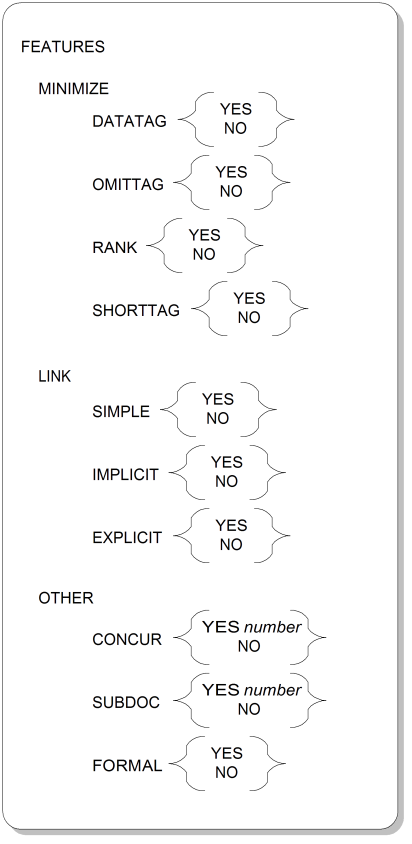
The feature use parameter indicates which optional features of SGML the document uses. Figure A.16, “FEATURES Parameter Syntax” shows the syntax for the feature use parameter.
FEATURESKeyword for the feature use parameter.
MINIMIZEKeyword that groups the feature use settings for minimization.
DATATAGSetting indicating whether or not data characters can simultaneously serve as tags.
OMITTAGSetting indicating whether or not certain tags can be omitted entirely. If this setting is YES, element declarations must specify omitted-tag minimization rules. Section 8.6, “Designing Markup Minimization” discusses this kind of minimization.
RANKSetting indicating whether or not certain elements have several ranked incarnations, such that the rank of any one instance (indicated by a number appended to the generic identifier) can be inferred if omitted.
SHORTTAGSetting indicating whether or not shortened-tag minimization is used. Section 8.6, “Designing Markup Minimization” discusses this kind of minimization.
LINKKeyword that groups the feature use settings for the link feature. Note that the link feature is not related to hyperlinking, but rather to the association, by SGML means, of markup and content with stylesheet and other procedural computer behavior.
SIMPLESetting indicating whether or not simple link process definitions are used.
IMPLICITSetting indicating whether or not implicit link process definitions are used.
EXPLICITSetting indicating whether or not explicit link process definitions are used.
OTHERKeyword that groups the feature use settings for miscellaneous features.
CONCURSetting indicating whether or not an instance can conform to multiple document types concurrently. Specify the number of allowed document types in addition to the base document type in number.
SUBDOCSetting indicating whether or not an instance can contain SGML subdocument entities (which might conform to a different document type). Specify the number of allowed subdocument entities in number.
FORMALSetting indicating whether or not public identifiers must conform to the rules for formal public identifiers (discussed in Section A.10, “Formal Public Identifiers and Catalogs”).
Figure A.17, “APPINFO Parameter Syntax” shows the syntax for the application-specific information parameter.
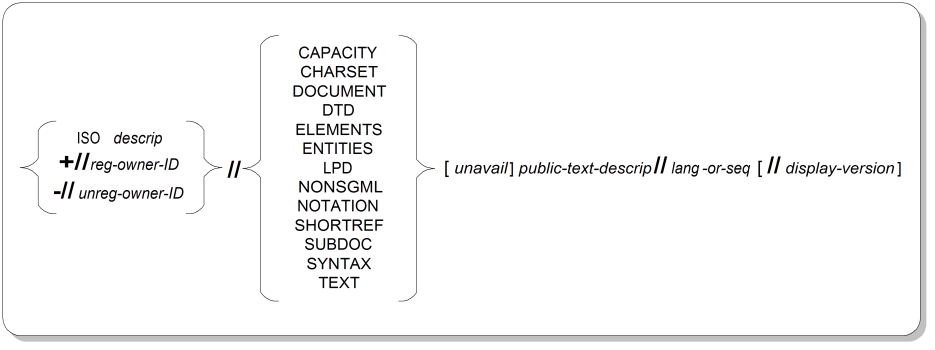
Public identifiers appear in entity declarations as “logical names” that stand for the physical locations of the entity's publicly available replacement data. A public identifier can be formal or informal; only formal identifiers must conform to the constraints shown in Figure A.18, “Formal Public Identifier Syntax”.
ISO descripIndicator that the public text is owned by ISO. Public text defined by ISO 8879, such as the entity sets for characters and symbols, uses its publication number, “8879:1986” ,as the description. Other ISO standards use their own publication numbers.
ISO 8879:1986//...
Note that ISO-owned public text has only one pair of slashes before the appearance of the keyword labeling the kind of public text.
+//reg-owner-IDIndicator that the public text has an owner who is registered according to ISO 9070, the standard governing the registration of owner identifiers for SGML public text. In this case, the owner ID is composed of an assigned prefix and, optionally, one or more further fields preceded by double colons, which qualify the description of the precise owner. Currently, other than identifiers directly connected to ISO publications or other organizations duly authorized by ISO to issue prefixes, the only acceptable owner prefix is an International Standard Book Number (ISBN) preceded by the string “ISBN ”.
+//ISBN 0-933186::IBM//...
-//unreg-owner-IDIndicator that the public text has an unregistered owner.
-//Joe's Bar and Grill//...
CAPACITY etc.Keywords indicating the nature of the public text. The keyword values are explained in Table A.7, “Formal Public Identifier Keywords” .
unavailIndicator that the public text is generally unavailable, that is, its owner allows only certain people to have access to it. If the text is available, this entire field is left out. If the text is unavailable, the unavail field consists of a hyphen followed by two slashes.
-//Ept Associates//DTD -//...
public-text-descripString describing the contents of the public text. If the text is owned by ISO, the public text description must consist of the last part of the publication title.
-//HyConcept Inc.//DTD Manual//...
lang-or-sequenceString further qualifying the public text. In the case of CHARSET public text, it is a string containing a character set designating sequence, as defined by ISO 2022. Otherwise, it is a two-letter code in uppercase indicating the natural language used in the text, as defined by ISO 639. For example, “EN” stands for English.
-//ALF Inc.//DTD Memo//EN
display-versionString distinguishing this set of public text from others that differ only in the display device or system to which they apply.
-//DEC//ENTITIES Tech chars//EN//troff
The display version specification can't be used with the keywords CAPACITY, CHARSET, NOTATION, and SYNTAX.
Table A.7, “Formal Public Identifier Keywords” explains the keywords that identify the public text referred to by a formal public identifier.
Table A.7. Formal Public Identifier Keywords
| Default Value | Description |
|---|---|
CAPACITY |
Capacity set for use in an SGML declaration. |
CHARSET |
Character set specification for use in an SGML declaration. |
DOCUMENT |
|
DTD |
Set of markup declarations comprising a DTD. |
ELEMENTS |
Set of element declarations and other related markup declarations for use in constructing a DTD. |
ENTITIES |
Set of entity declarations for use in adding entities to a DTD easily. |
LPD |
Entity sets, link attribute sets, and link set declarations that comprise a link type declaration. |
NONSGML |
Entity containing non-SGML data. |
NOTATION |
Public notation declaration. |
SHORTREF |
Set of short reference specifications. |
SUBDOC |
Entity containing an SGML subdocument. |
SYNTAX |
Concrete syntax specification for use in an SGML declaration. |
TEXT |
Entity containing SGML text (including data and/or markup). |
The mechanism for mapping a public identifier to a physical storage location must be recorded externally to an SGML document, which allows entity declarations to be portable across systems. Each SGML-aware software package uses some form of mapping file to record the information.
The SGML Open consortium has issued Technical Report 9401, which specifies a standard format for a “catalog file” that maps public identifiers (as well as other SGML constructs, such as whole SGML declarations) to “storage object identifiers.” A storage object identifier is typically a filename or pathname, but it could also be, for example, be a database query that returns the necessary data, or a World Wide Web uniform resource locator (URL). Most SGML-aware software products and public-domain packages now support the SGML Open catalog format, meaning that catalog files are becoming more portable across systems.
The catalog syntax for the mapping of a public identifier to the entity data is as follows:
PUBLIC "public-identifier" "storage-object-identifier"
Appendix E, Bibliography and Sources describes how to get more information on catalog files and SGML Open.